
For years, the likes of Sam Altman have spun a seductive narrative: scale up the models, and AGI - Artificial General Intelligence - will emerge, ushering in an era of abundance where every problem is solved automatically. The pitch is simple: just keep feeding the beast more data and compute, and soon, the world’s knowledge will be at your fingertips, ready to transform every business and every life. This hype has led to massive spend and huge valuations, but here’s the inconvenient truth: the way LLMs (large language models) actually work means they can never deliver on this promise. The dream of AGI as a universal problem-solver is built on sand.
LLMs work in a probabilistic way, which means they guess the most likely next word or answer based on patterns - not fixed rules. Because of this, if two people ask the same question, they’ll get different responses, and you can’t guarantee what answer you’ll get each time. Scaling up the model size doesn’t fix this - LLMs will always be probabilistic by nature. The problem gets even worse if the knowledge the model uses is disconnected or contains contradictions, since the model might pick up on those inconsistencies and give even more unpredictable or conflicting answers. In business and everyday life, people usually need deterministic outcomes, where the same input always gives the same, reliable result. Deterministic systems are important because they make things predictable and trustworthy. The unpredictable nature of LLMs makes them a poor fit for situations where accuracy and consistency really matter.
If AGI was really coming by next year and so magical, why did OpenAI and Anthropic need to get into bed with private equity to build a consulting company, guaranteeing them returns just to get AI into businesses? If AGI could truly do what’s promised, it would integrate itself into every workflow with the ease of a self-assembling IKEA shelf. Instead, we’re watching the world’s most advanced “intelligence” being baby sat by a bunch of consultants with MBAs.
They need those consultants to try and add probabilistic functionality into businesses that need deterministic outcomes.
The Context Crisis: Why LLMs Alone Will Never Be Enough
The reality is that LLMs, for all their power, are context-blind. As Stanford’s recent study made clear, these models can’t reliably distinguish fact from fiction - they treat every context as equally plausible, whether it’s a business plan or a bedtime story. This is why, for LLMs to be useful in business (or even for consumers), they need a context and orchestration layer: a deterministic system that extracts, verifies, and delivers the right facts at the right time.
A recent Microsoft study further reinforces the limitations of frontier models when used in isolation. The research found that even state-of-the-art LLMs, when tasked with executing real-world business workflows - such as updating records, generating reports, or handling customer queries - frequently made subtle but critical errors if not guided by a structured orchestration layer. The study concluded that without explicit context management and fact verification, these models often hallucinate, misinterpret instructions, or propagate outdated information. This is absolutely no surprise as they are probabilistic in nature, put simply it's impossible to guarantee they can do the same thing twice without a deterministic layer.
This evidence in both of these papers underscores that simply scaling up model size does not translate to reliable business execution; it is the orchestration layer - curating context, enforcing business logic, and auditing outputs - that transforms raw AI potential into dependable, actionable results.
This orchestration layer is the unsung hero of the AI stack. It’s what enables platforms like NOAN to deliver accurate, actionable answers - by curating the context, auditing the facts, and ensuring that the AI’s output is grounded in reality. The LLM becomes just a tool, sitting atop a foundation of structured, auditable knowledge.
The Frontier Model Fallacy
The truth is, no business today actually needs a so-called “frontier” model. Even if you handed most companies the best model from two years ago - say, GPT-3 or its peers - and embedded it within a robust orchestration layer with a well-structured context stack, they could automate and execute every meaningful business need: sales outreach, customer support, content creation, analytics, and more. The bottleneck isn’t the raw intelligence of the model; it’s the absence of a system that reliably delivers the right facts, at the right time, in the right workflow. The relentless chase for ever-larger models is a distraction from the real work of building context-driven, auditable, and actionable AI systems that actually move the needle for businesses.
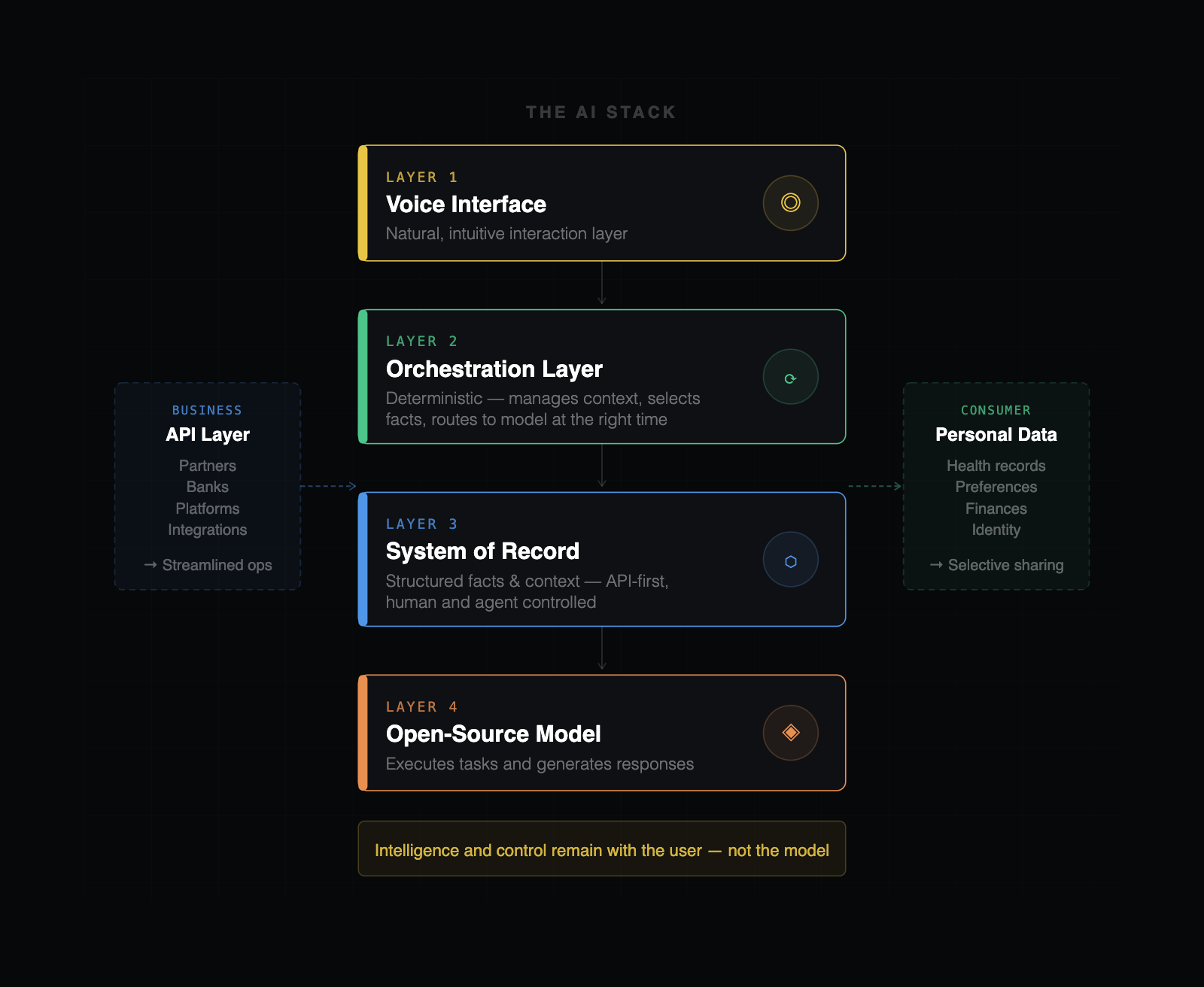
The Real Disruption: Context Orchestration, Not Model Size
When we talk about the “AI stack,” we’re describing the foundational layers that make up a modern AI-powered system - whether for business or consumer use. In the future, this stack will be defined by four core components: a voice-based user interface for natural, intuitive interaction; a system of record that stores a user’s or business’s key facts and context as structured data on an API that humans and agents can control; a deterministic orchestration layer that manages context, selects relevant facts, and ensures the right information is delivered at the right time; and an open-source model that executes tasks and generates responses. This architecture allows seamless integration - businesses might expose their API-based facts to partners like banks for streamlined operations, while consumers could selectively share personal data (such as health records or preferences) with trusted platforms. Crucially, the intelligence and control remain with the user or business, not locked inside a proprietary model, enabling flexible, secure, and context-rich AI experiences.
As Jack Dorsey recently described, this new architecture acts like a “mini AGI” for a company - a living, always-updated intelligence that anyone can interact with directly. Instead of relying on static org charts or siloed documents, the company’s knowledge, relationships, and decision history are woven into a dynamic context that both humans and AI agents can access and build on. This means every team member, partner, or tool can “talk to” the company’s collective intelligence, making decisions faster, with more clarity and confidence.
Here’s where the real threat to the AI bubble emerges. The right orchestration layer- one that selects and delivers the right facts as context - doesn’t need a massive, expensive context window. It doesn’t need a single, monolithic “frontier” model. In fact, if you believe (as we do at NOAN) that the future interface is voice-based, then the requirements for AI shrink dramatically.
In the end, every interface will need to do just three things: generate text, respond with voice, or create visuals on demand. The orchestration layer can call on the best available model for each task - for instance a smaller, open-source model - rather than relying on a single, all-powerful LLM. And as every business and individual moves their facts and knowledge onto an API, the need for a “frontier” model disappears entirely.
This is because when a business’s or consumer’s facts are structured as an API - instantly accessible by both agents and humans - the need for “frontier” model capabilities fades away. We’re no longer relying on static platforms like PDFs or spreadsheets that require brute-force reading and interpretation. Instead, we’re simply asking our agents or platforms to deliver precise answers or render the exact views we need, on demand. This shift means much of the heavy lifting that today’s AI models perform - summarizing, extracting, or searching through unstructured data - becomes obsolete. The intelligence is in the orchestration and accessibility, not in the size or novelty of the model itself.
The funny thing is sci-fi writers saw this future coming, there's a reason why you never seen anyone in a sci-fi movie ask an AI to open a PDF.
What's more building this on a stack with open source models adds a layer of trust and empowerment that has been lacking to individuals and businesses. All of a sudden users are not reliant on the privacy policy of a big tech provider, but their own complete AI stack. As Mozilla CTO Raffi Krikorian put it recently 'you don't want to necessarily trust privacy policies, you don't want to trust documentation. I want to trust architecture, I want to know that it's built in a way that you can't extract my data. Those are the fundamental things we've got to fix'.
One thing to keep in mind is that much of the current AI hype is driven by the revenue models of LLM companies, which are built around tokens and token spend. If you spend just five minutes using any major LLM product, it quickly becomes clear how many tokens are wasted - thanks to poor context and sloppy execution. This inefficiency isn’t just frustrating; it’s a direct result of the fundamental limitations of LLMs when used alone. With the right context and orchestration layers in place, token usage drops dramatically, making AI not only more effective but also far more efficient. It's why companies should be rewarding employees who build the architecture to one shot requests to LLMs in their companies, not those that token max.
The Future: Full-Stack, Voice-First, Open-Source
So what’s coming next? Two things:
- Hardware-Integrated, Context-Aware AI: Companies like Apple will move smaller, specialized models onto devices, powered by the right context and orchestration layers. (We have already seen the first wave of this with the MacMini trend...)
- Full-Stack AI Platforms for Business and Consumer: These platforms will be built around privacy, voice UIs, context management, and orchestration - using open-source models for execution. This gives everyone, from solo founders to global enterprises, full control of their AI stack.
This future puts control, privacy, and flexibility back in the hands of individuals and businesses. By building on open-source models and transparent orchestration layers, individuals and organizations are no longer dependent on the whims or opaque algorithms of big tech giants. Governments, too, can support and adopt platforms that align with their own values and regulatory needs, without being forced into partnerships with monopolistic providers. This approach fosters greater innovation, accountability, and trust - ensuring that AI serves the interests of society as a whole, rather than concentrating power in the hands of a few.
AI will deliver on its promise - not as a monolithic, closed system run by OpenAI, but as a modular, open, and fully controllable stack. The future isn’t AGI as a magic brain in the cloud. It’s orchestration, context, and open-source models - giving power back to businesses and individuals, and finally making AI what it was always supposed to be: a tool, not a black box.
And that, ironically, is the one thing the current AI giants never saw coming and it's probably the biggest threat to their bubble inducing business models.